NLP Concepts Part 1
Some basic ideas in natrual language processing
Sep 27, 2021 by Xiang Zhang
When I entered the field of natural language processing, I learned many interesting ideas. Here I would like to share some of them.
1. Language model
A language model can predict the next word when given a sequence of words, or to be more precise, predict the probability distribution over a predefined vocabulary.
Before deep learning's domination in natural language processing, a language model is basically a large lookup table, recording frequencies of different combinations of words' occurrences in a large corpus. Now it's a neural network trained on a corpus or dataset.
In addition, a causal language model(e.g., GPT) predicts the next word, and a masked language model(e.g., BERT) fills the blank given the rest of a sentence.
If you input "The man ____ to the store" to BERT, it will predict the blank most likely to be one of these words: "pointed", "returned", "nodded", "turned", "gestured". And probabilities are 0.21, 0.15, 0.13, 0.06, 0.04, respectively.
2. Word embedding
A mathematical way to represent a word with a vector is called word embedding, e.g., embedding("king") = [0.9, -0.5, 0.8, 0].
This method is reasonable as we express a word's meaning with multiple dimensions of numbers. It has several benefits. One is that, when we determine the similarity of two words, we can use their embedding vectors' dot product. It's convenient and efficient. Another one is that, word embedding vectors have analogy property. For example, "king" - "man" = "queen" - "woman", or "woman" - "man" = "queen" - "king". This interesting property gives us a hint about vectors' meaning. Some dimensions may related to gender, some others may related to royalty. We can even use this property to remove the bias of a language model. Furthermore, when we process a word as a vector, we can leverage deep learning models. We put vectors into the neural network, to do a classification task that we care in a forward pass. Or we use loss function's derivatives with respect to every weights to learn the whole model, or embedding function itself, in a backward pass.
3. BLEU and ROUGE
BLEU stands for bilingual evaluation understudy. It's an automatic metric to evaluate how close a sequence of text generated by a language model is to a reference. At first, it's used to evaluate the quality of machine translation text. Now other natural language processing tasks such as task-oriented dialogue generation adopt it as well.
For a reference "The man returned to the store", a generated text "the the man the" would get a BLUE score as below.
For each word in the generated text, we count the total length(3 "the" and 1 "man") as the denominator, and for those appear in reference, we count the sum(2 "the" and 1 "man") as the numerator, then we get "unigram precision":
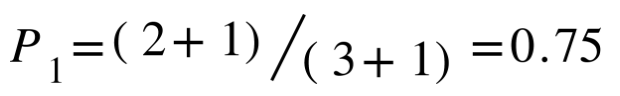
Then for every generated consecutive two words, we count the total number of combinations(1 "the the", 1 "the man", 1 "man the") as the denominator, and each combination appears in reference, we count the sum(0 "the the", 1 "the man", 0 "man the") as the numerator, then we get "bigram precision":
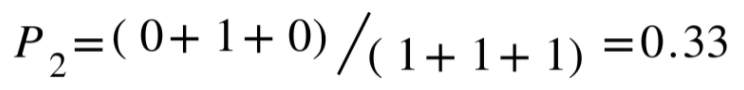
Similarly, we can get "trigram precision":
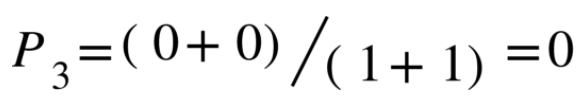
After that, we take the exponential of the mean of three precisions to represent kind of an average precision:
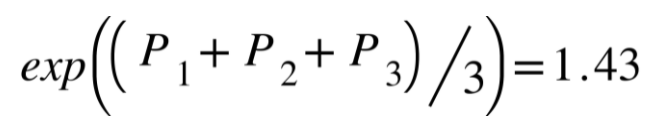
You can use as many "grams" as you like, the idea is the same. Computing resource is the limit.
Finally, as a short generated text tend to have a higher BLEU score compared to a long one, we need to multiply a "brevity penalty" to the score if generated text is shorter than the reference. Brevity penalty is defined by
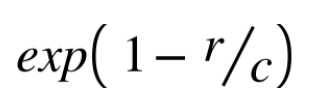
where r is the length of the reference, and c is the length of the generated text. For the example above, the BLEU score is
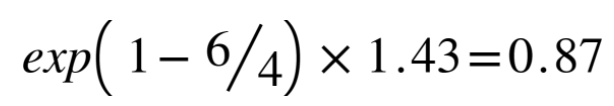
ROUGE stands for Recall-Oriented Understudy for Gisting Evaluation. It's like a recall version of BLEU and it's mainly used in summarization task. When we do a binary classification, precision is the proportion of true positives in all positive predictions, while recall is the proportion of true positives in all true ground truths. The same idea is applied to ROUGE.
For the example above, we get the reference length 6 as the denominator, and we count the sum of every generated word appears in reference, 2 "the" and 1 "man", as the numerator, then we get "unigram ROUGE", or ROUGE-1 :
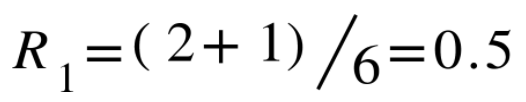
Similarly, we get "bigram ROUGE", or ROUGE-2:
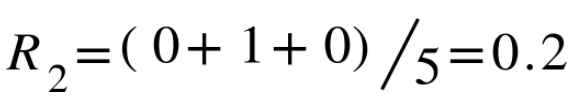
4. Summary
In this blog, we discussed NLP concepts: word embedding, language model, BLEU and ROUGE metric. If you have any suggestions, or want to quote this blog, please leave a message below. Thanks for reading.
