How to Improve Performance of Deep Learning models
Some efficient ways to improve performance of AI models
Sep 9, 2021 by Yan Ding
We will first go through some strategies often used to improve the performance of deep learning/machine learning models. Secondly, we need to fingure out problems of the model, such as "high bias", "high variance"etc, so we can decide to use which stategy. Moreover, we may need to do error analysis to manually examine errors.
1. Some strategies often used for deep learning models
Given an example, if we train a classification model to recognize whether it is a cat, we got the accuarcy of 90%. Compared with human-level performance which may be 99%. The performance of our model is not good enough. Usually there are some ideas we can try, for example,
- Collect more data.
- Collect a more diverse training set.
- Train algorithm longer with learning rate decay.
- Try another optimation algorithm such as Adam instead of gradient descent.
- Try a bigger or smaller network.
- Try regularization, dropout.
- Change the architecture of neural network. i.e. Using EfficientNet instead of ResNet-50.
Here comes the problem. Which way to go?

Firstly, we need to figure out our main problem of the model so we can save our time and make much progress. Meanwhile, we can also get some expectations in the direction we chose. Generally we need first take a look at overfit and underfit problem.
2. Overfit and underfit problem
Simply speaking, overfit means that the model can get a very high accuracy on training data but performs quite poor in val/testing data. It is because it "overfits" to the training data. While underfit means the model performs poor in training data. Sometimes we may have both overfit and underfit problems.
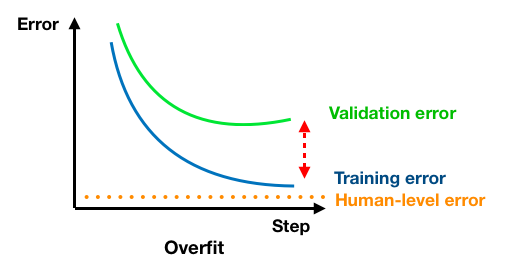
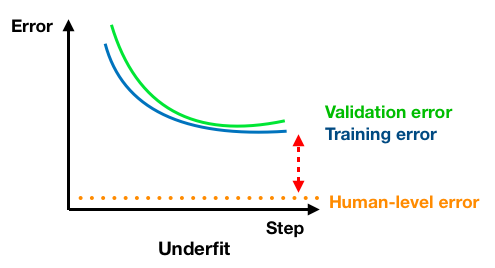
2.1 Definition of variances, bias
Let's first recap the definition of variance and bias to better understand the overfit and underfit problems. Firstly, "Variance" means the difference between training error and validation/test error. That means whether the model is able to generalize from training set to val/test set. Fig1 above shows the high variance case.
Secondly, "Bias"means the difference between training error and 0 or human-level error. Specially, the difference between training error and human-level error also refers to the "Avoidable Bias"[1]. Fig2 above shows the high bias case.
To sum up, these three definitions can be drawn as below:
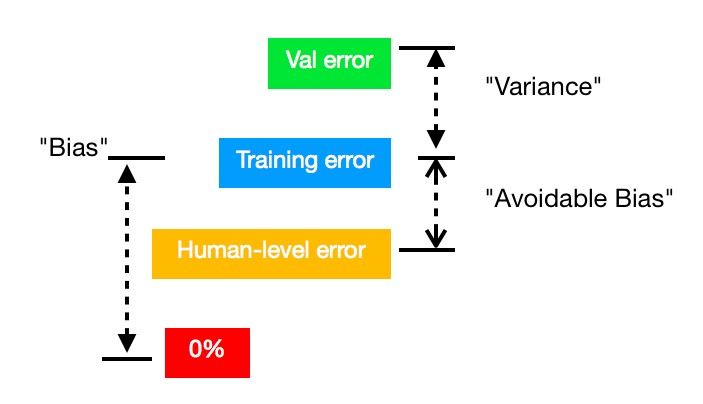
2.2 How to deal with Overfit problem?
Now we understand basic concepts of variance and bias. When we got high variance, we know it is an overfit problem. As the example of "recognizing a cat", supposing human-level error is 1%, training error is 1% and val error is 5% as below:

Hig variance means the training set cannot be generalized to val/test sets. There are several methods of reducing high variance as following:
- Collecting more data.
- Regularization such as L2 regularization, dropout, data argumentation.
- Try smaller neural network.
2.3 How to deal with Underfit problem?
When we got high bias, we know it is an underfit problem. Same example of "recognizing a cat" with 5% training error, 6% val error as below:

Bias is 4% while variance is only 1%. So we need to reduce the high bias. There are several methods we can do:
- Try larger model.
- Train longer/better optimization algorthim.
- Try other NN architectures such as CNN.
It is worth of time to first figure out main problem of the model and then try the most promising way to improve the performance.
3. Error analysis
The situation is usually more complicated in actual project. Sometimes we may need to manually find out mistakes that the model is making. This process is called error analysis.

As the example of "recognizing a cat" above, supposing we have achieved 90% accuracy or equivalently 10% error on validation dataset. We want to know what is misclassified as a cat. We need to collect 100 (for example) mislabeled examples and examine them manually. And list the true class, source etc. which is misclassified as following table:
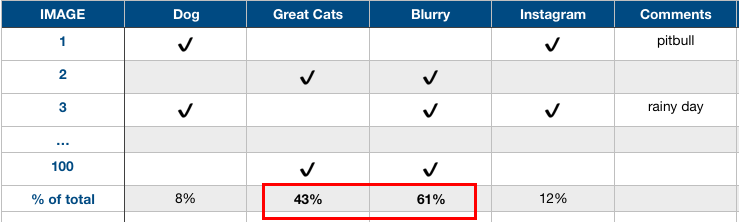
After counting up misrecognized images and we can get the percentage of each class. A lot of the mistakes were made on "Great Cats" and "Blurry" images . So if we can do better in these images, maybe collecting more data of great cats or adding image augmentation, our model performance can be improved in much extent.
Let's do a simple calculation. Recall the error on val dataset is 10%, so the error can be potentially reduced by 4.3% or 6.1%. Please be careful that one image can be in multiple categories of the table. While no matter how better we can do in "Dog" or "Instagram", the error can only be reduced by 0.8% or 1.2%. This process can give us a sense of the best options to pursue.
Moreover, we can also add new categories of errors in above table. For example, we found a lot of mistakes are caused by incorrectly labeled data. If the dataset is very large, it seems not realistic to re-label all the data. But it will affect the evaluation of the model. So we can first correct the val/test data to ensure get the true evaluation of the model. Although deep learning models are robust to random errors, it cannot do well in "Systematic Errors". For example, if a labeler consistently labeled white dogs as cats, that is a problem because the model will learn to classify white dogs as cats. In that case, we will need to correct the training data as well.
To summarize, it may a little boring to manually examine errors but it can actually give a promising direction to improve your system performance. Spending a few hours to do manual error analysis can actually save a few months you may spend on a less worthwhile direction.
4. Summary
In this article, we discussed how to find main problems of the deep learning model such as overfit and underfit. So we can get the most promising ways to improve the deep learning model. Moreover, we introduced how to do error analysis so we can improve the system more efficiently. Thank you for your reading!
